This year’s public data file is now available, featuring over 156 million metadata records deposited with Crossref through the end of April 2024 from over 19,000 members. A full breakdown of Crossref metadata statistics is available here.
Like last year, you can download all of these records in one go via Academic Torrents or directly from Amazon S3 via the “requester pays” method.
Download the file: The torrent download can be initiated here.
Earlier this year, we reported on the roundtable discussion event that we had organised in Frankfurt on the heels of the Frankfurt Book Fair 2023. This event was the second in the series of roundtable events that we are holding with our community to hear from you how we can all work together to preserve the integrity of the scholarly record - you can read more about insights from these events and about ISR in this series of blogs.
Crossref is undertaking a large program, dubbed 'RCFS' (Resourcing Crossref for Future Sustainability) that will initially tackle five specific issues with our fees. We haven’t increased any of our fees in nearly two decades, and while we’re still okay financially and do not have a revenue growth goal, we do have inclusion and simplification goals. This report from Research Consulting helped to narrow down the five priority projects for 2024-2025 around these three core goals:
The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
Expressions of interest will be due Monday, May 27th, 2024
This is an exciting time to join the board, as we have a number of active projects underway: We are considering resourcing Crossref for a sustainable future and board members will be part of deciding any changes to our fees scheme and overseeing its implementation.
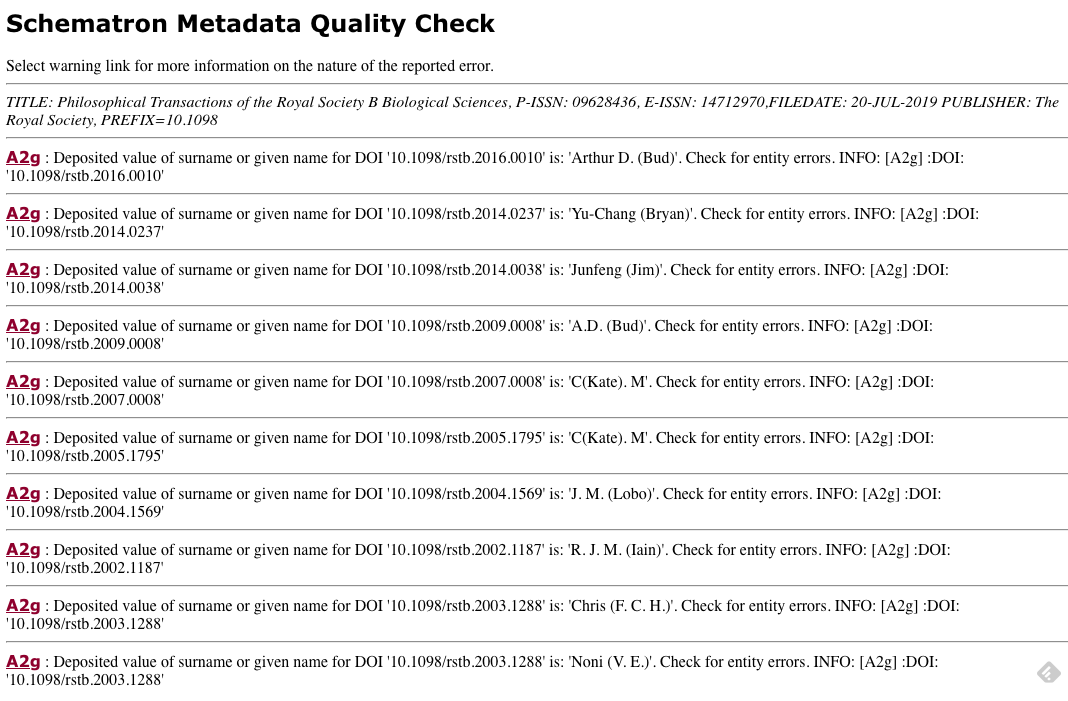
A Schematron report tells you if there’s a metadata quality issue with your records.
Schematron is a pattern-based XML validation language. We try to stop the deposit of metadata with obvious issues, but we can’t catch everything because publication practices are so varied. For example, most family names in our database that end with jr are the result of a publisher including a suffix (Jr) in a family name, but there are of course surnames ending with ‘jr’.
We do a weekly post-registration metadata quality check on all journal, book, and conference proceedings submissions, and record the results in the schematron report. If we spot a problem we’ll send you an alert. Any identified errors may affect overall metadata quality and negatively affect queries for your content. Errors are aggregated and sent out weekly via email in the schematron report.
What should I do with my schematron report?
The report contains links (organized by title) to .xml files containing error details. The XML files can be downloaded and processed programmatically, or viewed in a web browser: